

ETL processes are buckling. Every new API, sensor, or app dumps more data into the queue, each requiring its own manual setup. Teams get stuck writing the same rules to clean the same errors, a cycle that burns time and patience. We think the real shift is using AI to handle this drudge work, letting engineers tackle actual problems. This approach, which we call data engineering with AI, isn’t magic. It’s a practical tool for a specific, growing headache.
The New Reality of Data Engineering
The old model of predictable, batch-processed data is gone. Now you’ve got live streams, messy JSON blobs from third-party tools, and unstructured text all hitting your systems at once. When a source changes its schema without warning, it breaks everything downstream. Teams relying on manual checks miss these shifts.
They end up in firefight mode, cleaning up messes instead of building anything new. It’s exhausting and frankly, a waste of talent.
How AI is Changing ETL and Data Processing
AI doesn’t ‘reinvent’ the wheel. It just applies pattern recognition to automate the tedious parts of data work. The idea is to make pipelines less fragile. This happens in a few key areas, moving from simple rules to systems that can make basic inferences.
Large-scale systems often follow a pipeline structure like this, where ingestion, transformation, and monitoring flow through an orchestrated process.
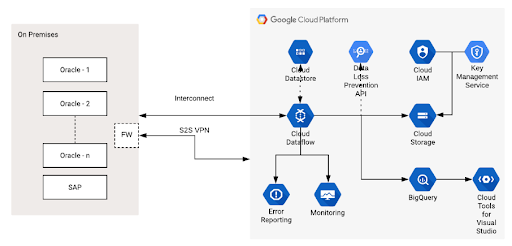
Smarter Ingestion and Classification
At the point of ingestion, algorithms can now scan incoming data. They guess at formats, spot weird outliers right away, and suggest a structure. It’s not perfect, but it cuts down the manual setup for a new data source from days to maybe a few hours. The system provides a good first draft.
Cleaner Transformations and Faster Mapping
Transformation logic is a mess of business rules. AI works here like a simple helper. It learns from past jobs and reduces the amount of manual mapping work. Before these transformations go live, teams often rely on AI for a few common tasks:
- It suggests basic field mappings based on previous patterns.
- It spots duplicate records that don’t match exactly.
- It flags values that look off before they break a pipeline.
These quick checks shave off a lot of manual steps and speed up development.
Better Monitoring and Orchestration
Monitoring gets an upgrade. Instead of just alerting you after a job fails, it analyzes trends to warn you that a failure is likely. It might notice rising memory consumption in a job and suggest rescheduling it before it crashes and takes other processes down. You move from static schedules to something more adaptive.
Benefits of AI-Driven ETL
The value shows up in everyday work. Teams spend less time fixing the same issues, pipelines run more smoothly, and engineers finally get space to focus on real projects instead of constant maintenance.
Look at the tangible outcomes:
- Development cycles for new pipelines get shorter,
- Manual data cleansing effort drops hard,
- You catch errors before they poison your analytics,
- Infrastructure costs come down through smarter execution,
- Engineers get time back for real projects.
That last point matters. Morale improves when people stop babysitting brittle jobs.
Challenges Slowing Down AI Adoption in ETL
The tech exists, but most companies aren’t built for it. Procurement cycles are a killer. By the time a new AI tool gets approved, the problem might have already changed. Legacy systems create a huge integration wall. Your shiny new AI needs to talk to a decade-old database, and that’s a whole project itself.
Many data teams are also too busy keeping basic operations running to test new tools. Governance adds more pressure. Any system that touches customer data requires strict approval, and this review process can take months. By the time everything is cleared, the original problem may have already shifted. That is the usual pace inside large organizations.
Practical Use Cases of AI in ETL Pipelines
AI in ETL is not a theory anymore. Teams are already using it in places where the payoff is obvious and the problem is well-defined. A few real examples show how it works in practice:
- E-commerce firms use language models to sort millions of messy product titles from suppliers, saving thousands of manual tagging hours.
- Banks run anomaly detection on transaction feeds, halting suspect batches before they enter the ledger.
- Streaming services automatically unify user profiles across different devices and platforms, using fuzzy logic to guess when two IDs are the same person.
- Shipping companies forecast when their nightly data loads will strain systems and spin up extra cloud capacity preemptively.
These aren’t science projects. They’re targeted fixes that save money and reduce risk.
Choosing the Right AI Tools for ETL Automation
Picking a tool is messy. Compatibility is the first hurdle. You need to know whether it will work with your current stack or push you toward a full rebuild. Then comes the explainability problem. If the AI changes a mapping rule, you need to understand why. A black box does not work in environments where every change must be auditable.
Open-source libraries give you full control but demand deep in-house expertise. Enterprise platforms are easier to start with, but they can lock you into a specific ecosystem. In practice, the choice often depends on how much your team wants to build on its own versus how much speed and support you need right now. There is no single correct option.
Many teams eventually consider enterprise platforms with built-in AI features because they offer an integrated path from ingestion to processing. This reduces the amount of custom engineering required at the start.
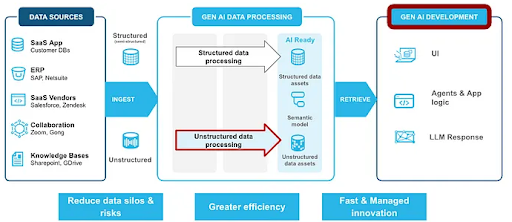
When Teams Need External Engineering Expertise
Building these systems requires a mix of skills: data plumbing, machine learning, and software engineering. That combo is rare in one person, let alone a whole team. Sometimes you just need to bring in help to get over the initial hump. An external partner makes sense in a few spots:
- Your team knows data but hasn’t deployed production machine learning models before.
- The timeline is tight, and there’s no room for a six-month learning curve.
- You need to connect old, on-premise systems to new cloud-based AI services.
- You have to build a convincing prototype fast to unlock budget for a larger project.
In these cases, working with specialists in data engineering with AI can cut through the complexity. They’ve seen the common failures and can help you avoid expensive mistakes, letting your own people focus on the business logic.
The Future of Automated Data Pipelines
The direction is clear: less manual intervention. We’ll see more pipelines that adjust their own schedules based on cost and data flow predictions. Schema changes might be proposed and tested by the system itself. The idea of a pipeline that detects a broken transformation and rolls it back automatically is becoming real.
This changes the engineer’s job. It shifts from writing every single transformation rule to designing the system that writes them. They become more like overseers, setting policy and solving the weird edge cases the AI can’t handle. The grunt work gets automated, but the need for sharp, experienced engineers actually goes up.
Conclusion
AI in data engineering solves a specific problem: the unsustainable load of manual, repetitive pipeline management. The result is fewer errors and engineers who aren’t burned out on tedious tasks. AI isn’t replacing anyone. It’s taking the thankless work off their plates so they can do the complex, interesting stuff that actually moves the business forward. That’s the whole point.